AIアートの新時代2:Stable Diffusionの課題と動画生成の新潮流
- 物販商品(倉庫から発送)ネコポス可能紙版+電子版¥ 2,500
- ダウンロード商品電子版¥ 1,900
- ダウンロード商品無料試し読み¥ 0無料ダウンロードai_art_2024_mihon.pdf(25.8 MB)ai_art_2024_mihon.pdf
「AIアートの新時代」の続編がついに誕生! 2022年~23年にStable Diffusionが一世を風靡しましたが、それ以降も着実に研究が進化し、画像生成モデルのカスタマイズが体系化され、動画生成モデルが台頭しつつあります。特にOpenAIのSoraの発表以降、Transformerベースの画像/動画生成モデルが盛んに研究され、『アートの主戦場は、「動く」世界へ』となっています。 本書の序盤では、画像生成モデルのStable Diffusionの課題として「スタイル統一の問題」を挙げます。例えば、同一プロンプトでも結果が安定しなかったり、スタイルが思ったものとかけ離れているなどの問題に当たることは多いです。この問題について、LoRAの訓練の工夫、LoRAなしでスタイルを統一する技術、生成画像の定量評価など様々な切り口から見ていきます。 本書の後半では、動画生成モデルの台頭を、論文の解説とコードの実行の両方から体感していきます。2024年以降急速に広まりつつある、DiT(Diffusion Transformer)についても集中的に見ていきます。OpenAIの動画生成モデル「Sora」についても背景技術をキャッチアップできるようにしています。また、3次元復元の入門として、nerfstudioによるNeRFを実装ベースで体験していきます。 前作:https://koshian2.booth.pm/items/4820110
本の仕様
B5 / 152P / オフセットフルカラー ※「紙の本+電子版」の場合は、電子版は「おまけファイル」からDLできます
各章の紹介
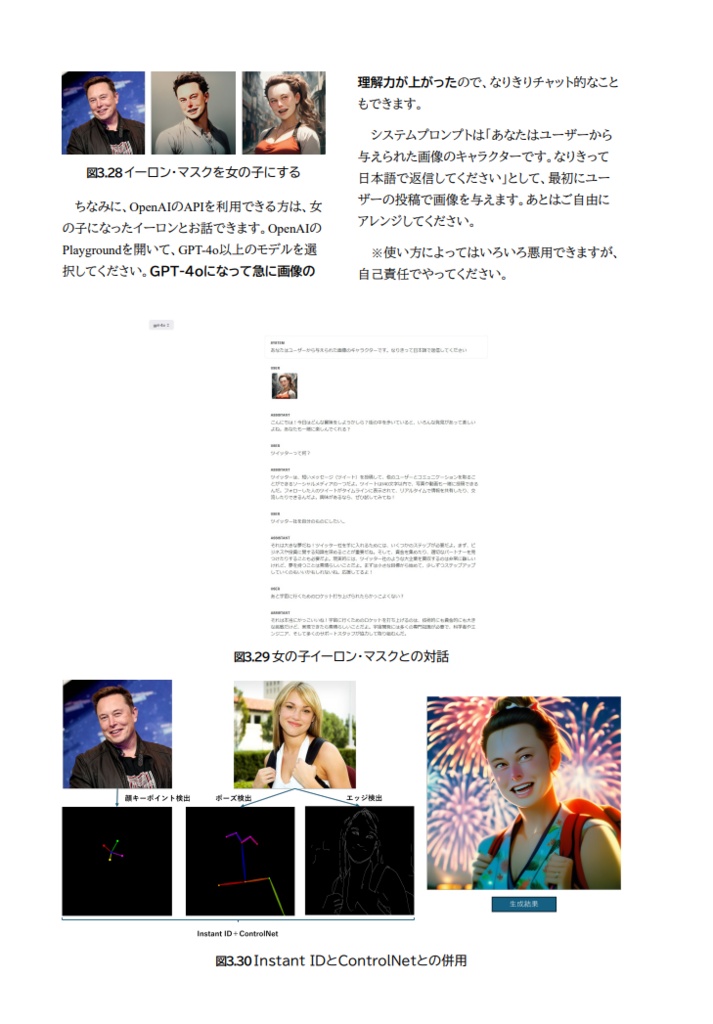
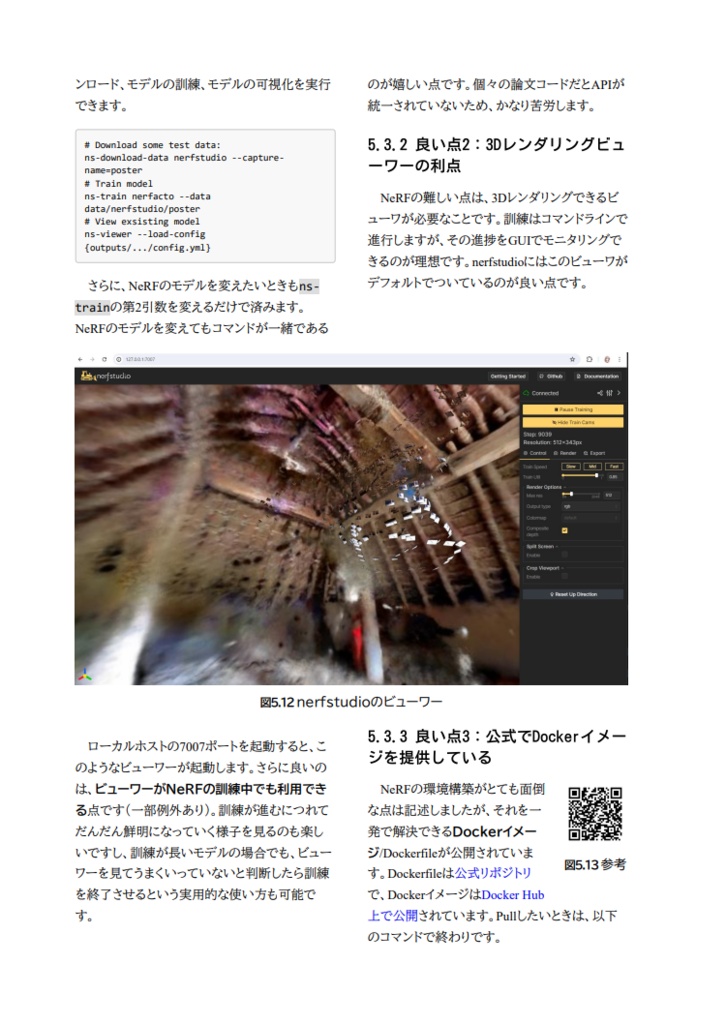
1. 画像生成モデルの進化の歴史:Stable Diffusion以降(p.7) 第1章では、画像生成モデルの進化を年表形式で振り返ります。OpenAIやGoogleをはじめとする主要なプレイヤーがどのように技術を発展させてきたか、DALL-EシリーズやImagenの進化、Stable Diffusionシリーズの最新技術、さらに低訓練コストで注目されるPixArtシリーズ、ロシア発のKandinskyモデルなどを詳細に紹介します。技術的背景から最新のトレンドまでを網羅し、画像生成の進化をまとめます。 2. LoRAを効率的に訓練する技術(p.21) この章では、LoRA(Low-Rank Adaptation)の訓練方法に焦点を当てます。LoRAの概要から、Parameter Efficient Fine Tuningの手法、具体的な訓練ライブラリや環境構築方法、そしてキャプション自動生成技術について詳述します。特に、sd-scriptsを使用したLoRAの訓練や、Dockerを活用した環境構築方法、VLMを活用したキャプション自動生成など、実践的な内容に注力しています。 3. 生成画像のスタイルを統一する技術(p.47) 第3章では、生成画像のスタイル統一技術について紹介します。IP AdapterやStyle Alignedといった技術の理論から実践方法までを詳述します。具体的には、Attention機構やDecoupled Cross-Attentionの仕組み、ControlNetの併用方法、Adaptive Instance Normalization (AdaIN) の理論と実践について取り上げます。また、顔画像に特化したInstant IDのセットアップ方法や、アニメモデルでの応用例なども解説します。 4. 画像生成の定量評価(p.68) この章では、画像生成モデルの定量評価の重要性と具体的な方法を紹介します。トム・ミッチェルの機械学習の定義を引用しつつ、CLIPやDINOを用いたEmbeddingベースの評価方法、FIDによる特徴量ベースの評価、さらにAesthetics PredictorやHPSv2などの美的評価モデルについて詳述します。また、訓練済みCLIPを使った独自の評価予測モデルの作成方法についても具体的に説明します。 5. nerfstudioで始める3次元復元の基本(p.88) この章では、3次元復元技術とNeRF(Neural Radiance Fields)の基本原理について説明します。特に、nerfstudioというOSSを活用して、NeRF特有の環境構築の煩雑さを解消する方法や、スマホデータを用いた手軽な3次元復元方法を紹介します。また、Gaussian Splattingやnerfactoの技術詳細、カメラやセンサーデバイスとの連携についても詳述します。 6. 動画生成の進化と新潮流(p.110) 第6章では、動画生成技術の進化と新潮流について詳述します。特にAnimateDiffを中心に、Text2Video、Image2Video、Video2Videoといった各タスクを実際に操作してみる方法や、Soraといった次世代動画生成モデルの技術詳細を取り上げます。さらに、LatteやI2VGen-XL、Pose2Video、Video2Videoの最新技術についても説明し、動画生成の未来を展望します。
リポジトリ
本書のリポジトリは以下の通りです。本書の著作権は著者が保持しますが、コードはMITで利用できます。 https://github.com/koshian2/ai-art-book-2024
対象
・画像生成やコンピュータービジョンの機械学習興味ある人や専門家
対象技術レベル
・AIや基本的な画像生成の話は、1巻やその他の本で飽きるほど書いているのでこの本ではしません ・Dockerやdocker-composeは既知のものとします ・画像生成や動画生成の論文の話を結構します。正確には数えていないですが、関係する論文だけで50本以上はあると思ってください ・著者が「書いてて楽しかったな」と感じるレベルなので、一般人にカルピスの原液そのまま飲ませてるようなものかもしれません ・Stable Diffusion WebUIやComfy UIの話はしません
環境
・ローカルGPUがある想定で書いています。VRAMは最低16GB、望ましいのは24GBです。以下のような制約がおきます ・~16GB:SDXL+ControlNetを動かすとあふれる、動画生成は相当無理がある ・~24GB:SDXL+ControlNetが余裕持って動く、動画生成は動くことは動く(たまにあふれることはある) ・24GB~:動画生成が余裕を持って動く ・ColabやクラウドGPUでも原理的に動きますが、特にそのための配慮はしていません。ColabはDocker使えない点は注意してください。 また、ダウンロードする重みが大きめなので、Colabはランタイムリセットに気をつける必要があります。
アップデート
・v0.0.0:5/25 1~3章(現:2~4章)を公開 ・v0.0.1:5/26 4章(現:5章)の半分を追加 ・v0.0.2: 5/28 4章(現:5章)が出来上がり ・v0.0.3: 6/1 5章(現:6章)のAnimateDiffまでを追加 ・v0.0.4: 6/3 5章(現:6章)のSoraの進化とLatteを追加 ・v0.1.0: 6/5 6章が完成、1章に新たに画像生成モデルの歴史について追加 ・v1.0.0: 6/8 全部完成し、正式版公開。入稿も完了し、入庫に間に合う見込みです ・v1.0.1: 6/9 目次を微修正
Buyee経由の注文に注意
ブラウザの言語環境が「日本語以外」で「紙の本を含む」場合、「Buyee」経由の注文となることがあります。 これは海外発送代行サービスであり、日本在住の方は使う必要はありません。日本在住の方は「日本語のページ」から、ネコポスなどで発送するようにしてください。 Buyee経由ではBoothの注文履歴に反映されないため、おまけの電子版がダウンロードできません。